1. The headline: in 2025 and 2026, the LLMs are winning. And one of them is winning a lot
For most of the past decade, "which translation engine should I use?" was a boring question. DeepL covered European languages, Google Translate covered the rest, and most localization teams treated all of them as interchangeable inputs into a post-editing workflow. The interesting decisions were upstream: the glossary, the style guide, the post-editor.
That is no longer true. Our 2025 to 2026 sample tells a different story.

The 2025-onward mean for each major engine, ranked by Alconost Quality Index (AQI):
| Engine | AQI (2025+) | Linguist Eval (2025+) | Sample (AQI / LE) |
|---|---|---|---|
| Gemini | 77.7 | 67.8 | n=274 / n=381 |
| Anthropic (Claude) | 75.6 | 58.9 | n=309 / n=429 |
| GPT (OpenAI) | 73.1 | 57.6 | n=463 / n=557 |
| Mistral | 71.9 | 51.2 | n=285 / n=378 |
| Deepseek | 71.5 | 51.4 | n=169 / n=168 |
| DeepL | 70.8 | 50.0 | n=240 / n=336 |
| AutoML (Google AutoML) | 70.7 | 49.3 | n=218 / n=316 |
| Grok | 70.3 | 50.7 | n=241 / n=339 |
| Amazon Translate | 69.9 | 45.7 | n=215 / n=314 |
| ModernMT | 69.1 | 42.9 | n=154 / n=154 |
| Microsoft Translator | 67.9 | 40.1 | n=155 / n=155 |
Sample column shows AQI evaluations / Linguist Evaluation samples separately because LE is captured for a slightly larger subset of rows.
Two things to take away from this table.
One: the top three are all general-purpose LLMs (Gemini, Claude, GPT). The dedicated translation engines that defined the previous decade, including DeepL, Amazon, Microsoft, and ModernMT, sit in the bottom half. That gap was not there in 2023.
Two: Gemini's lead is not subtle. It beats Claude by 2 AQI points and GPT by 4.6 points. On linguist evaluation, where a human professional actually reads the output, the gap widens to 9 points. That gap shows up across languages, across content types, and it has been growing through 2025 and 2026.
If you are starting from "we should probably try GPT-4 as a translator," our 2025 to 2026 data quietly disagrees with you.
2. How we measure: AQI, linguist evaluation, and why both exist
Quick detour before the per-language picture: how the numbers in this article are produced.
We score every engine evaluation on two parallel tracks.
AQI, the Alconost Quality Index, is a weighted blend of seven metrics. The weights are documented in the source dataset and align with what the academic and industry literature says about the strength of each metric:
- COMET (30%): a neural framework that correlates strongly with human judgment.
- LE, Linguist Evaluation (20%): a 0 to 100 score given by a professional native-speaker linguist. Always present in our calculation.
- nTER (15%): edit-distance metric that reflects post-editing effort.
- BERTscore (15%): contextual similarity using transformer embeddings.
- BLEU (10%): the historic n-gram precision metric, intentionally down-weighted because surface overlap is a known weak signal in 2026.
- CHrF++ (5%): character n-gram metric, useful for morphologically rich languages.
- COMET-QE / CometKiwi (5%): reference-free quality estimation.
AQI maps to a five-step quality scale: above 85 is near-human (minimal post-editing), 70 to 85 is acceptable (light to moderate), 55 to 70 is medium (moderate), 40 to 55 is low (heavy), and below 40 is reject-or-retranslate.
LE, Linguist Evaluation is the human track. We do not trust the automated metrics alone. The linguist score is what we ultimately recommend the engine on, and it is why this work costs more than running BLEU in a notebook. The structure of the linguist evaluation aligns with MQM error categories: accuracy, fluency, terminology, locale convention, style, design, and internationalization. You can see what an MQM-tagged review looks like, or run one yourself, using our MQM tool at alconost.mt.
The reason we run both tracks is the most useful single chart in this article.

A positive number means the automated metrics rate the engine higher than the linguist does. Every engine gets some flattering, since automated metrics reward fluent output and do not always catch terminology or context errors. But the spread is striking: Gemini's gap is less than half of Microsoft's. Buyers who pick an engine from a leaderboard built on BLEU and CHrF++ (which most public benchmarks effectively are) will systematically over-rate the engines that produce smooth-but-wrong output, and under-rate the ones that are more conservative but more accurate.
That is why a serious MT evaluation always pairs automated metrics with a human reviewer. It is also why "we ran a benchmark on our content" can produce different rankings than the engine vendors' published benchmarks, even when both are technically correct on the metrics they report.
3. The scoreboard, by language pair
The headline ranking masks meaningful per-language differences. Here is the picture for the top language pairs in our 2025+ sample.

The full 2025+ scoreboard with sample sizes:
| From English to | Best engine (AQI) | Runner-up | Comment |
|---|---|---|---|
| French (fr) | Gemini 80.0 (n=25) | Anthropic 79.3 (n=27) | tight race |
| Spanish (es) | Gemini 80.1 (n=19) | Anthropic 79.9 (n=30) | essentially tied |
| German (de) | Anthropic 78.2 (n=18) | Gemini 77.0 (n=15) | Anthropic narrowly |
| Italian (it) | Gemini 81.0 (n=12) | Anthropic 76.6 (n=16) | |
| Japanese (ja) | Gemini 72.5 (n=22) | Anthropic 71.2 (n=23) | |
| Chinese, Simplified (zh-CN) | Deepseek 72.2 (n=12) | Gemini 71.9 (n=17) | Deepseek's home turf |
| Portuguese, Brazilian (pt-BR) | Anthropic 81.0 (n=12) | Gemini 80.4 (n=13) | Anthropic narrowly |
| Turkish (tr) | Anthropic 79.1 (n=13) | Gemini 77.9 (n=13) | Anthropic narrowly |
| Korean (ko) | Gemini 78.2 (n=12) | Deepseek 70.7 (n=7) | |
| Polish (pl) | Gemini 79.7 (n=11) | DeepL 74.3 (n=11) | |
| Russian (ru) | Gemini 73.0 (n=9) | Anthropic 68.6 (n=10) | overall harder |
| Chinese, Traditional (zh-TW) | Gemini 74.4 (n=12) | Anthropic 74.2 (n=12) | virtually tied |
| Indonesian (id) | Anthropic 79.3 (n=7) | GPT 78.7 (n=15) | three engines within 1 point |
| Portuguese, European (pt) | DeepL 80.6 (n=8) | Gemini 74.3 (n=6) | the iberian split matters |
| Dutch (nl) | DeepL 80.0 (n=6) | ModernMT 80.0 (n=5) | small samples, NMT holdouts |
| Hungarian (hu) | Gemini 81.9 (n=6) | AutoML 77.0 (n=5) | small sample |
| Thai (th) | Gemini 75.0 (n=5) | Anthropic 68.2 (n=6) | small sample |
| Arabic (ar) | Gemini 78.6 (n=5) | Anthropic 76.8 (n=8) | small sample; DeepL had <5 samples in 2025+ |
In most language pairs, Gemini wins, with Anthropic close behind. The carve-outs are where this table actually pays off.
Deepseek wins on simplified Chinese. Not surprising once you say it out loud. Deepseek is a Chinese-trained model and the linguistic priors it brings to en→zh-CN are different from the priors a Western-trained LLM brings. If you are shipping a Chinese version and you are defaulting to GPT or Claude because that is what your stack already uses, this is the one cell in the table where the default is probably wrong.
Anthropic narrowly leads on several pairs. German, Brazilian Portuguese, Turkish, and Indonesian all show Anthropic ahead of Gemini, in each case by less than 2 AQI points. That is within natural sample variance; treat them as cells where Gemini and Anthropic are interchangeable rather than as a clean Anthropic win. The honest read is that for these languages, either of the top two LLMs is a reasonable production default.
DeepL still wins on European Portuguese. The pt-PT margin (80.6 vs Gemini 74.3) is real and persistent. If you are picking between DeepL and an LLM specifically on pt-PT, the data favors DeepL. The Brazilian Portuguese (pt-BR) and European Portuguese (pt) split is the one most translation budgets get wrong by treating "Portuguese" as one locale. They are different engines for different markets even though they share a language code root. The same kind of split should be checked carefully on Spanish (es-ES vs es-MX vs es-LATAM); we do not have enough samples broken out by sub-locale to publish that here, but the pattern holds in our experience.
Arabic is sparse in our 2025+ data. DeepL had a long-standing reputation as the strongest engine for Arabic, but our 2025 sample for DeepL on Arabic is below the n=5 threshold we use for inclusion. Gemini scored 78.6 on n=5 Arabic samples. We would not commit to either claim on a sample that thin. If Arabic is core to your project, run a project-specific evaluation before sourcing.
4. The interactive scoreboard: pick your slice
Pick any combination of industry, content type, and target language. The selector returns the top engines for that exact slice if we have enough samples; otherwise it falls back to the closest combination we do have data for, and tells you which one.
5. The scoreboard, by content type
Different content types stress engines differently. Marketing copy needs voice. Legal content needs terminological precision. Game UI needs to fit in a button. Here is the per-content-type picture from 2025+.

- UI / In-App Content (the largest content category in our sample, n=1,203 in 2025+): Gemini 81.0 → Anthropic 79.2 → GPT 77.9 → Mistral 76.6. Gemini's lead is tighter here than elsewhere, and GPT closes the gap on shorter, structurally constrained UI strings.
- Narrative Content (long-form copy, articles, in-product narrative text, n=1,132): Gemini 73.5 → Anthropic 71.5 → Deepseek 70.0 → GPT 68.2. Surprisingly close cluster; the choice often comes down to voice consistency across a long document, which is a per-project judgment more than a per-engine one.
- Marketing & SEO (n=128): Gemini 82.9 → Anthropic 78.5 → Grok 77.1 → Mistral 76.7. Gemini has the largest margin here, which fits the model's reputation for fluent, idiomatic prose. For tone-critical marketing copy, the data supports Gemini as the default. This is also the content category where MTPE matters most, since "fluent and wrong" is the failure mode that hurts a campaign.
- Online courses (n=132): Anthropic 75.5 (n=12) → ModernMT 75.0 (n=6) → Gemini 74.9 (n=14) → Grok 73.6 (n=13). The top three are within a point of each other; do not pick on this margin alone.
- Documents (long-form, structured documents, n=65): AutoML 81.6 (n=5) → Gemini 79.0 (n=10) → DeepL 78.7 (n=6) → Grok 75.2 (n=9). AutoML tops the table on a thin sample; treat as suggestive.
- Legal (n=35 total, n=5 per top engine): Gemini 84.6 → DeepL 80.3 → Mistral 74.3 → Grok 71.9. This is the smallest cell in our content data and the most counter-intuitive result. DeepL has marketed itself for years as the right choice for legal and regulated content. In our 2025+ sample, on the legal content we processed, Gemini scored 4 points higher. Sample size is genuinely small (n=5 per engine) and the AQI differences here are within plausible variance. Run your own evaluation before choosing an engine for high-stakes legal content. The era when "DeepL for legal, period" was a defensible default is closing, but our data is not strong enough alone to declare a successor.
- Support materials (n=20 total): Anthropic, DeepL, GPT, and AutoML all within 2 points. Sample is genuinely too small to rank confidently.
The pattern across content types is consistent with the cross-language picture: Gemini is the default winner across the largest cells, with a handful of explicit carve-outs. If you only remember one decision rule from this article, it is this one: Gemini, except when you have a specific reason not to. The rest of the article is the list of specific reasons.
6. The scoreboard, by industry domain
Some industries reward specific engines more consistently than others.
| Industry | Best engine (AQI) | Runner-up |
|---|---|---|
| Games & Entertainment | Gemini 73.8 (n=118) | Anthropic 72.0 (n=120) |
| IT & Software Development | Gemini 81.3 (n=59) | Anthropic 79.1 (n=87) |
| Privacy & Security | ModernMT 74.4 (n=10) | Anthropic 72.0 (n=18) |
| Education & E-Learning | Anthropic 85.6 (n=20) | GPT 82.6 (n=67) |
| Financial Services & Banking | Gemini 84.6 (n=11) | DeepL 79.2 (n=12) |
| Automotive | Gemini 79.5 (n=12) | Grok 75.6 (n=12) |
Two anomalies worth flagging.
Education content goes to Anthropic. Across the cluster of engines we tested on education and e-learning content, Claude scored noticeably higher on linguist evaluation than Gemini did, and high in absolute terms (85.6 AQI is well into the "near-human" band, n=20). Claude's general reputation for following structured instructions and not hallucinating registry shifts probably contributes to this.
Privacy & Security content goes to ModernMT, but not for the obvious reason. The ModernMT result on Privacy & Security is real and replicable on the data we have, but it is also a single-customer effect: the project that produced most of the ModernMT samples in this domain had a heavy in-house glossary and a mature translation memory. ModernMT is one of the engines that benefits most from your existing language assets. The headline lesson is not that ModernMT is the right Privacy & Security engine; it is that language assets matter. A clean glossary, a current style guide, and a well-maintained translation memory will move quality more than switching engines will, especially on engines that integrate cleanly with them.
This is also where a vendor with depth in language-asset management is worth paying for. If your translation memory is fragmented across two platforms, your glossary is six months out of date, or your style guide lives in a Slack DM, the engine ranking will not save you. Engine selection is the easy half of the question; running an AI translation workflow well is the hard half.
7. The data has an expiry date
Everything above is dated. The first question we get when we share rankings like these is "will this still be true in six months?" The answer is no.
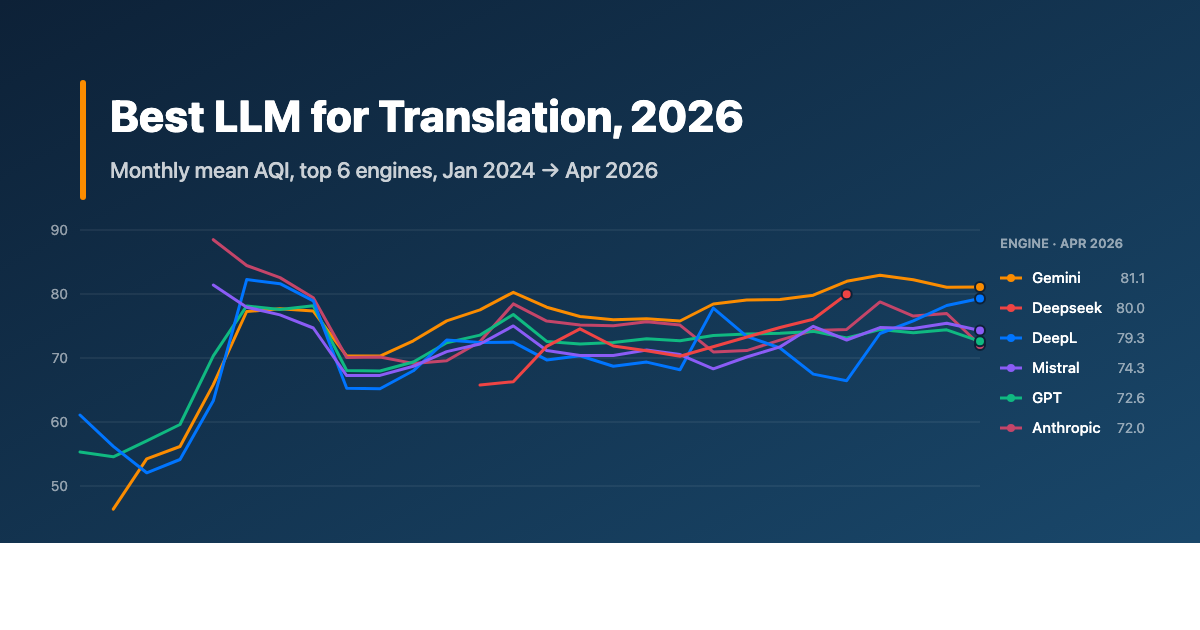
Here are the same three engines (Gemini, Claude, DeepL) in quarterly buckets across 2024, 2025, and 2026:
| Period | Gemini AQI | Anthropic AQI | DeepL AQI |
|---|---|---|---|
| Q1 2024 | 46.4 (n=7) | no data | 56.2 (n=29) |
| Q2 2024 | 65.8 (n=19) | 88.5 (n=6) | 63.3 (n=18) |
| H2 2024 | 73.1 (n=129) | 70.1 (n=128) | 69.1 (n=105) |
| H1 2025 | 76.8 (n=210) | 75.7 (n=205) | 69.6 (n=171) |
| H2 2025 | 79.1 (n=33) | 72.6 (n=31) | 71.6 (n=30) |
| 2026 (Jan to Apr) | 82.2 (n=31) | 76.5 (n=73) | 75.5 (n=39) |
A few observations.
The early-2024 numbers are sparse. The Q2 2024 Anthropic spike (88.5) is on a six-sample cell and should not be read as "Claude was best in mid-2024"; it is a small subset of evaluations where Claude happened to score well. By H2 2024 all three engines had stabilized at meaningful sample sizes, and the trajectory becomes readable.
Through 2025, Gemini built a roughly 3-point lead, then extended it. Anthropic wobbled, with a strong H1 followed by a weaker H2 followed by recovery in 2026. DeepL has improved meaningfully in 2026 (its 2026 AQI is the highest it has been in our data), driven mostly by gains on its weaker languages, though it still trails the LLM leaders.
The implication for buyers is uncomfortable: the right engine this quarter is not necessarily the right engine next quarter. Engines update silently. The Gemini you tested in May is not the Gemini you are translating with in November. Most teams that commit to a single MT vendor for a year do so on a stale evaluation.
The fix is not to avoid commitment; it is to commit, then re-evaluate. We recommend a full re-evaluation per project per quarter, with lighter sampling between. This also catches the rarer failure mode where an engine quietly regresses on a specific language pair after an API update, which we have seen at least three times in our 2025 data.
8. What this means for your project
The scoreboard above is the easy part of the answer. The hard part is what to do with it.
Picking the highest-scoring engine for each language and content type is a reasonable starting point. It is not the whole answer, for three reasons.
One: language assets matter more than the baseline. A glossary, a style guide, and a clean translation memory will move quality on a "second-place" engine more than switching to "first place" without those assets will. The engine evaluation tells you the ceiling; your language assets determine how close you actually get to it. Engines like ModernMT, AutoML, and Mistral gain noticeably more from a strong TM and glossary than the LLMs do.
Two: prompting and fine-tuning move the needle for LLMs. A vanilla Gemini call and a Gemini call with a glossary, brand voice instructions, and a few example translation pairs will produce very different output, on the same content. None of the numbers in this article involve project-specific prompting; they are baseline comparisons. With prompting, the ceiling moves up. Rankings can also shift, sometimes dramatically.
Three: review is not optional. Every engine in our top tier has a Linguist Evaluation score in the 50s or low 60s on a 0 to 100 scale. That is good translation by previous-decade standards. It is not ship-ready translation for content that touches a customer. The data argues for a layered workflow: engine selection, then targeted prompting, then MTPE with human review, then linguistic QA on the build for anything inside a UI. Skipping the human layer is the failure mode these rankings are most likely to invite, because the better the engines look on a scoreboard, the more tempting raw-AI deployment becomes.
This is the case for an MTPE workflow rather than an unmanaged engine API call. We will spare you the sales pitch.
9. How we approach MT engine evaluation
For context on how the numbers above were produced, here is the process we run on every project where engine choice matters:
Define the scope
Identify languages and content type. Set quality expectations: fluency, accuracy, terminology adherence. Pull glossaries, style guides, and reference materials. Prepare and format test files for optimal MT input.
Select MT engines
Choose from domain-specific NMTs and LLMs. Develop custom prompts for LLM-based pre-translation. Ensure proper configuration of selected engines and prompts. The pool is project-specific and gets smaller as the data narrows the field.
Run the MT evaluation
Translate the test sample using all selected engines under identical conditions for unbiased comparison. Up to 14 engines are evaluated on the same content sample.
Score on the metric stack and on linguist evaluation
All engines get the seven-metric AQI calculation (COMET, LE, nTER, BERTscore, BLEU, CHrF++, COMET-QE). Every output is also read by a professional native-speaker linguist in the relevant content domain. The linguist scores fluency, accuracy, terminology, and overall usability, and notes specific error patterns. This is the slow step. It is also the step that produces the AQI-vs-LE gap chart, and the reason our rankings can be trusted.
Recommend, document, and re-test on a cadence
The recommendation goes back to the project: which engine, for which language, with what prompting and language-asset configuration, and how often it should be re-evaluated. For most active projects the answer is "every quarter, with lighter monthly sampling."
This is how the data in this article was produced. It is also the work we would do on any project where engine selection affects quality at scale. The process slide and methodology summary are part of every project kickoff we run.
10. Limits and the fine print
Sample composition. Our dataset reflects the projects we ran in 2025 and 2026: heavily weighted toward games, IT and software, privacy and security, and education content, and toward English-as-source. Industries we are under-weighted in (healthcare, financial services beyond payments, government, hospitality) will not be well-represented in the per-domain rankings; treat those rankings as descriptive of our sample, not as an industry benchmark.
Sample size. Cell sizes vary. Where we have quoted a top-engine winner with fewer than ten samples (Vietnamese, Dutch, Hungarian, Thai, Arabic, several content and domain combinations), we have flagged it inline. A small sample winning by a small margin is not the same as a large sample winning by a large margin. Treat small-n cells as suggestive and run your own evaluation before committing.
Linguist evaluation. Each LE score is produced by a single professional native-speaker linguist working in the relevant content domain. This introduces a degree of subjectivity which we mitigate through consistency in scoring rubrics aligned with MQM error categories and through linguist QA over time, but does not eliminate. Expect ±5 AQI / LE points of natural variance between expert linguists on the same sample.
Engine versions and configurations. The engines tested here are the versions and API endpoints publicly available through the relevant vendor APIs at the time of each evaluation. Engine vendors update silently and frequently. The Gemini, Claude, GPT, Mistral, and Deepseek APIs available in late 2025 are not the same products as the equivalent APIs available in early 2024, even where the version label looks the same. The data is current to the dates of evaluation, not to the day you read this article.
Prompting and language assets. Most evaluations in the dataset use baseline API calls without project-specific system prompts, glossary injection, or fine-tuning. With those layers added, the rankings can shift, sometimes substantially, in either direction. Project-specific results will not reproduce the table here exactly.
Past performance is not predictive. The 2024 numbers in this article are already mostly stale, because the engine landscape moved fast in 2025. The 2026 numbers will be stale soon. If you are making a multi-year sourcing decision off any single snapshot like this one, you are doing it wrong. Engine selection is a continuously re-evaluated decision now, not a once-a-year procurement event.
Vendor relationships and disclosure. Alconost has no commercial relationships with any of the engine vendors named in this article. We are not a reseller. We do not receive referral fees, affiliate commissions, marketing development funds, or any other compensation that would create a financial incentive to rank one engine higher than another. What we do sell, and the reason this article exists, is machine translation post-editing: the human-review layer on top of these engines. The ranking informs which engine we run on a project, but it does not change what we charge or how we deliver. That is the relevant disclosure: we have a commercial interest in the post-editing layer, not in any individual engine.
Trademarks. Gemini, Anthropic, Claude, GPT, OpenAI, ChatGPT, DeepL, Google Translate, Microsoft Translator, Microsoft Bing Translator, Amazon Translate, ModernMT, Mistral, Deepseek, Grok, Llama, Qwen, and any other engine names referenced in this article are trademarks of their respective owners. The article discusses these products in the context of measured performance on a defined sample; nothing here should be construed as a recommendation against, endorsement of, or warranty about any vendor.
FAQ
Which AI is best for translation in 2026?
Is GPT-4 good for translation?
DeepL vs Gemini: which is better in 2026?
Can I use AI translation without post-editing?
How often should I re-evaluate my MT engine?
Does prompt engineering change the engine ranking?
Where to go next
If you want to go deeper into the methodology, our AI translation workflows page walks through how we run a full AI plus human translation workflow on top of the engines above. The MQM annotation tool we maintain is a free way to see what an MQM-tagged review looks like before commissioning one.
For decision-stage reading: AI vs. Human Translation, MTPE Explained, and NMT vs. LLM cover where AI translation fits in a modern localization program. LQA vs. Proofreading covers the review layer for content inside a UI.
If you would like us to run this kind of evaluation on your own content, in your own languages, against the engine pool that fits your stack, we do that as a fixed-scope engagement. The deliverable is a per-language, per-content-type recommendation and a re-evaluation cadence that fits your release cycle. Get in touch.

Ilya has spent 10+ years helping companies scale globally through localization. As CCO at Alconost, he works directly with enterprise and SaaS clients on localization strategy, MT engine selection, and ROI optimization.