Posted by Margarita Shvetsova
NMT vs. LLM: Who Wins the Translation Battle?

In the recent few years, the localization industry has been buzzing about AI translations. We at Alconost have gained valuable insights and want to share, so we are starting a series of AI translation know-how.
This first article in the series will cover the basics as a quick start before we dive deep. Let’s compare two main AI technologies for translation tasks:
-
LLM (Large Language Models) referring to GenAI models like ChatGPT, Gemini, Anthropic, and
-
NMT (Neural Machine Translation) referring to models like DeepL, GoogleTranslate, Microsoft Translator.
By default, NMT engines are considered a good fit for standardized content like documentation, and LLMs are preferred for more creative and informal language. However, the choice gets complicated once fine-tuning, diverse language pairs and other aspects come into play.
To help you make informed decisions, we’ll discuss:
-
What technology stands behind NMT and LLM;
-
What strengths and weaknesses NMT and LLM models have;
-
Customizing NMTs and LLMs for your needs;
-
Data privacy issues and how to avoid them;
-
A must-do step when choosing the right AI model for your content.
How do NMT and LLM models work?
Both NMT and LLM models are based on complex neural networks and trained on massive datasets. What sets them apart?
NMTs were created specifically for translation, while LLMs do translation as just one of the many text generation tasks they can do.
As they were built for different purposes, they function differently. NMTs don’t ‘understand’ the text, they just translate it, but LLMs can ‘understand’ longer passages. This enables LLMs to analyze the content and generate culturally appropriate translations.

Key differences between NMT and LLM translations

Let’s take a closer look at these differences.
⭐ Output
NMT-based models are quite predictable: for popular language pairs and domains, they normally produce accurate, neutral-styled translations. Such translations still need adjusting to the style and editing errors, but that was expected.
However, their precision can be a double-edged sword: sometimes translations sound too literal and stiff.
NMT models struggle with:
⛔ Maintaining the same context across a piece of text — it leads to errors in consistency, style, and terminology;
⛔ Adjusting to a certain style (DeepL offers formal/informal style, but that’s it);
⛔ Translating figurative language (metaphors, idioms, puns, etc.)
💡 Some of these problems can be overcome by fine-tuning (fluency, consistency, terminology, style — to some extent), but unfortunately it’s not a silver bullet.
LLMs are much trickier. On one hand, they beat NMT models with:
✅ Fluent, natural-sounding translations;
✅ Handling figurative language;
✅ Maintaining context and consistency across longer texts;
✅ Catching and mimicking style and tone of voice;
✅ Ability to handle translations even without training on parallel texts and quick adaptation with just a few examples.
On the other hand, the creative side of LLMs can be a problem:
⛔ Random results without the right prompt: like mixing Simplified and Traditional Chinese in one translation;
⛔ May be inconsistent with tags and formatting;
⛔ May leave randomly untranslated words;
⛔ Hallucinations and making up non-existent words for low-resource languages;
⛔ Without fine-tuning or carefully chosen prompts, LLMs may be inconsistent in style and terminology.
As you see, without proper guidance LLMs may take too much freedom to experiment with your content. The best way to ‘tame’ them is to use well-crafted prompts and additional context (and sometimes fine-tuning).
⭐ Pricing
NMTs offer a simple and transparent pricing model: they charge only for the input content, and the input is calculated in characters. That’s it! When an NMT model goes through fine-tuning, the input is calculated in segments.
LLMs have a more complex pricing structure — they use tokens and charge for the input and output:

There are many intricacies involved in LLM pricing, so you may end up paying more with LLMs — despite the fact NMT rates are generally higher.
⭐ Speed
NMT models are fast and can be used for real-time translations, while LLMs are up to 100-500 times slower! For example, if it takes an NMT engine a few seconds to process a piece of content, LLM may need several minutes.
This difference gets especially noticeable and annoying with larger projects — you’d notice it for content with over 2000 words.
⭐ Customization
NMTs have limited customization capabilities: mainly it implies using TM (translation memory) and glossaries. NMT models fine-tuned with project-specific data produce impressive results.
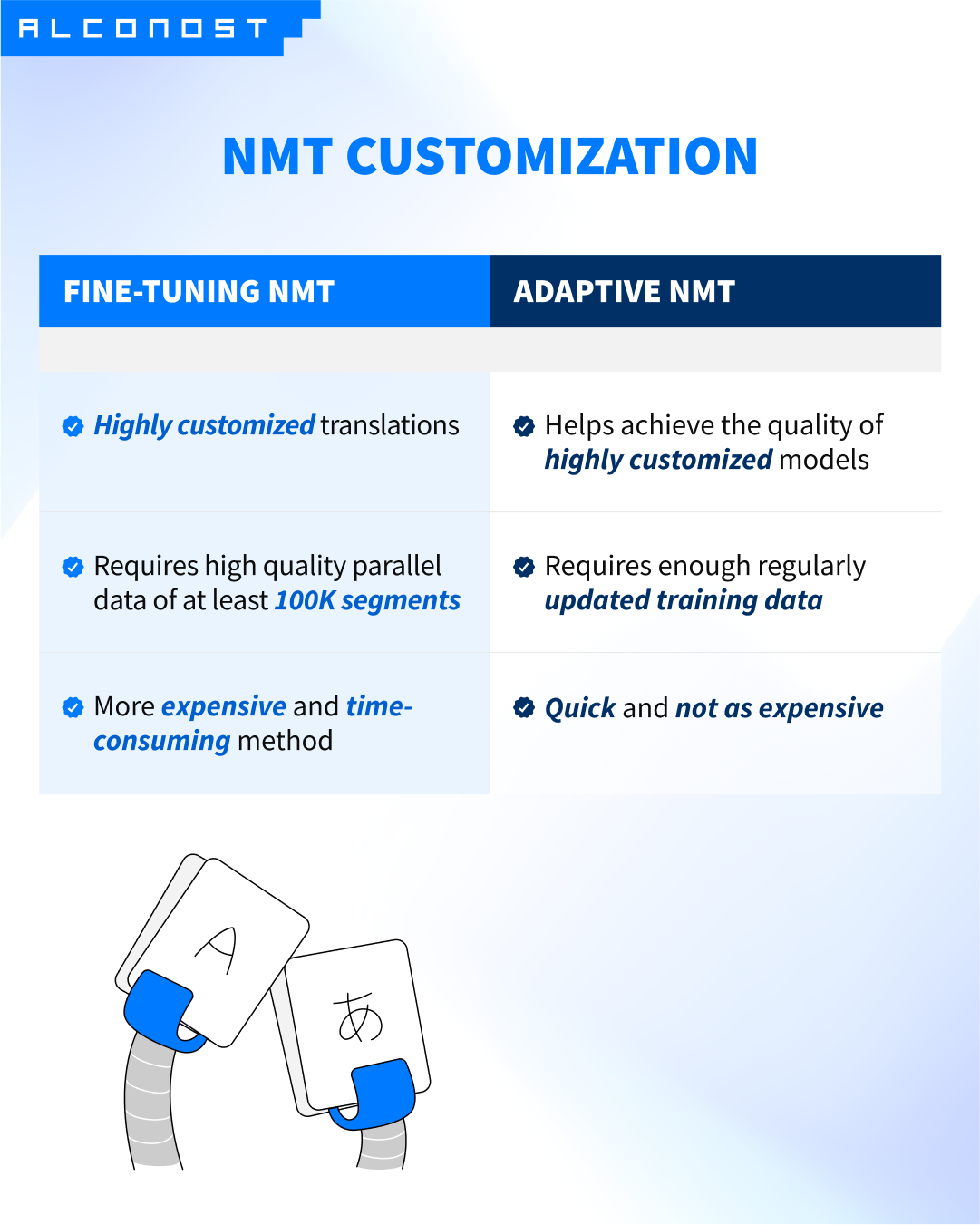
How to customize NMT:
-
Fine-tuning
You can train an NMT model with previous translations (TM). To make a real difference in quality, you’ll need a very large TM (at least 100K high-quality segments). This adds up to the price and takes a long time.
-
Adaptive NMT
This translation approach means you provide the model with a dataset of reference sentences, and the model accesses them in real time to customize its translations.
NMT models that support this approach: ModernMT, Amazon, Google AutoML.
LLMs, on the contrary, offer flexible customization opportunities. The most popular practices are prompt engineering and RAG.
Thanks to prompting, LLM models can understand and adjust to the following:
-
Tone of voice
-
Audience
-
Domain and content type
-
Consistency and terminology
-
Style
-
Cultural adaptation, etc.
It might be tempting to send one super long prompt to the LLM and think it’s done, but be careful — it may produce poor results.

The studies have shown that the effective context length of LLMs does not exceed 4K-8K tokens, and their performance declines dramatically at 32K tokens.
RAG (Retrieval-Augmented Generation) is one of the techniques that helps LLM look for relevant context in TMs (translation memories), reference translations, glossaries, etc.
How does it work? We instruct the model how to interact with this additional context: for example, we can ask it to look for similar content in the knowledge base and pick up the style.
🤔 Why use RAG if we have prompts?
There is a lot of information we put in the context window:
-
Text for translation
-
Prompt
-
TM
-
Glossary
-
Additional context (images, reference translations, etc.)
If LLMs get too much content to process at a time, their short-term memory gets overwhelmed, so to say, and they start ignoring some of this context. RAG is a workaround to this problem.
The RAG framework gives LLMs access to an external knowledge base when needed, without affecting their performance. Also, it provides the model with fresh, updated information without fine-tuning.
⭐ Efficiency across languages
Both NMT and LLM models show good results for high-resource languages like English, French, German, Spanish, etc. — that is, all languages with a vast amount of digital data available.
However, both stumble upon low-resource languages — those with limited digital presence, such as Finnish, Kazakh, Macedonian, Hindi dialects, African languages, etc. Non-English language pairs are especially challenging.

With some rare language pairs (like Japanese to Thai translations) or uncommon combinations of domain and language you may face the situation that no AI model can produce decent translations because of the lack of data. In this case, we try to find parallel data and fine-tune the model.
⭐ Security risks
Most NMT and AI models are open-source and trained on public information, and the ways they use this information are not always transparent.
The good news is that you can protect your data by running an LLM model on a private infrastructure.

The process of LLM deployment
What is best for translation, NMT or LLM?
From our experience, LLMs generally perform better. It’s important to note though that our conclusions are based on the verticals and types of content we specialize in:
-
Games
-
Apps
-
Software
-
Helpdesks
-
Marketing
-
eCommerce
-
Fintech
-
eLearning
That doesn’t mean we totally dismiss NMT models — they may be more efficient not only for very large volumes, but also for certain combinations of domain and language pairs. That’s why we always run tests on the client’s content to select best-suited models.
For example, it makes sense that UI content is not a good fit for NMT models. But models are constantly evolving, and our tests show that in some cases NMT models can tackle UI content successfully.
The bottom line is:
There are no ready answers to what AI model will do the job. Only tests can show what specific model(s) will work best for this particular content.
In our next article, we’ll show you what’s behind the scenes and how exactly we run these tests. Stay tuned!
Related articles

AI or Human Translation: Which One Fits Your Project Best?
Machine Translation
4 minutes read

MT is here to stay: how do we make it work for you?
Machine Translation
7 minutes read
Popular articles
Understanding Machine Translation and Post-Editing: 4 Common Questions
Machine Translation
7 minutes read
Best localization and translation platforms comparison
Apps localization
Nitro
12 minutes read
The Most Popular Languages for Localization in 2021: An Overview from Alconost
Apps localization
Global Markets
14 minutes read
Latest articles
No Playbook, No Problem: What Happens When You Trust Your Team with Something New
Game Localization
Success stories
4 minutes read
AI or Human Translation: Which One Fits Your Project Best?
Machine Translation
4 minutes read
Alconost Releases an Advanced Approach to Game Localization, Helping Developers Save up to 30% on Costs
Game Localization
5 minutes read
Have a project in mind?
We’d like to learn more about it. In return, we’ll get back to you with a solution and a quote.










